


A Tale of Two Rooms
At dawn, one board met in a quiet room in London, another in a bustling hub in Manila, and a dozen voices tried to find common ground. Hybrid meeting room solutions promised harmony, yet a single missed cue turned a big decision into a muddle. Recent room audits note that audio dropouts and translation delays still creep into more than a third of mixed‑format sessions—small glitches, large outcomes. So we ask: if the tech is modern, why does clarity still feel medieval?
In the early days, we overbuilt hardware and underplanned flow (too much gear, not enough design). Now we balance cloud tools, beamforming microphones, and smart routing, and still get edge cases—funny how that works, right? The heart of the matter is time: humans speak in streams; systems see packets. When timing slips, meaning slips. What follows contrasts old habits with lean choices so leaders can hear, decide, and move. Let us step into the deeper fault line and see what truly fractures under pressure.
The Hidden Gap in Interpretation Workflows
Why do old setups crack under load?
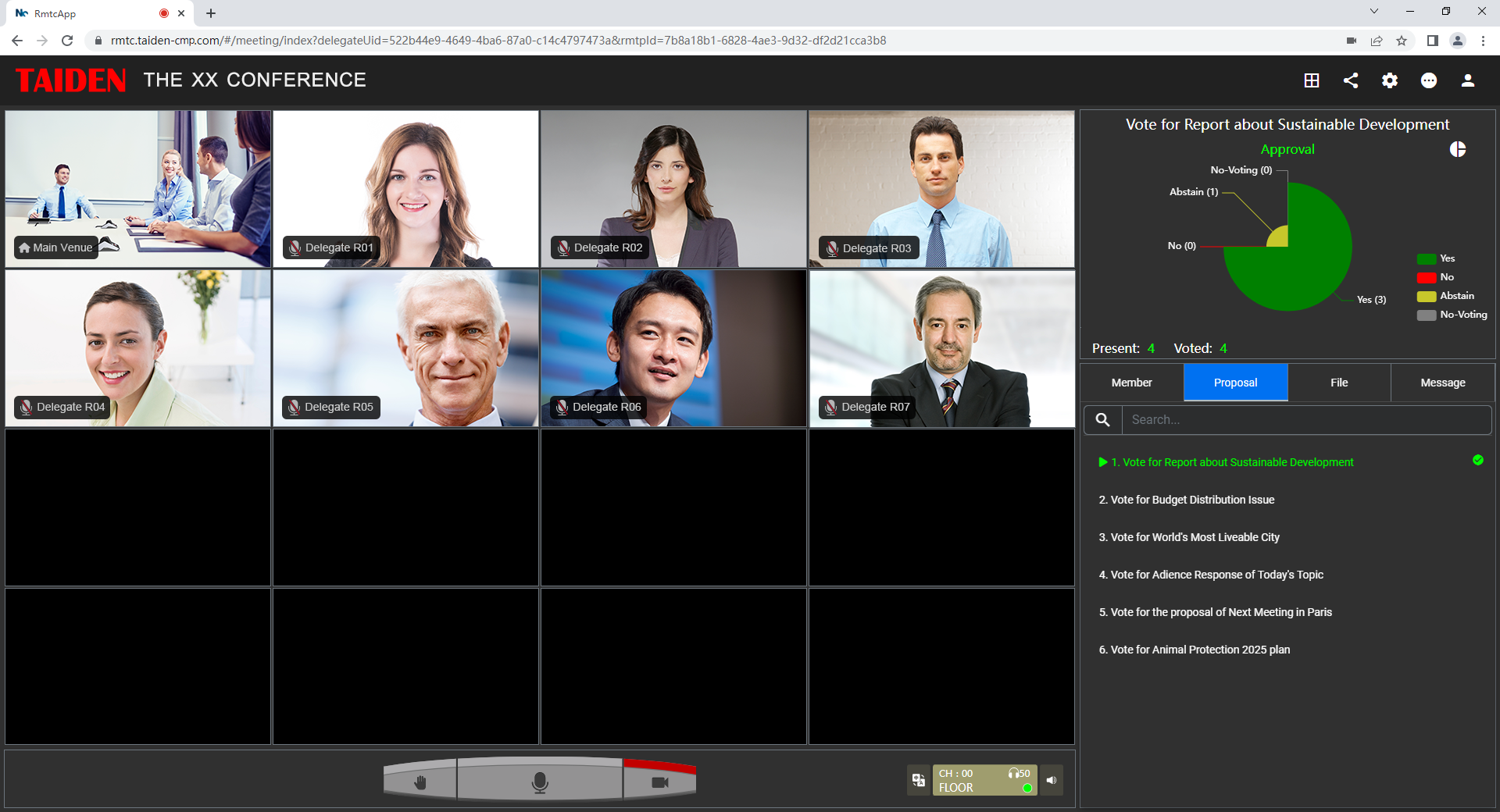
Technical answer: most traditional racks treated interpretation as a sidecar, not the engine. Analog loops, ad‑hoc channel maps, and “best‑effort” links made the floor language and interpreted channels compete for the same narrow path. In remote simultaneous interpretation workflows, two forces must align—ultra‑low latency and stable synchronization. When DSP chains grow long, the latency budget balloons. Add acoustic echo cancellation that is tuned for speech but not for multi‑channel feeds, and you get jitter that translators must “fill” with guesswork. Beamforming arrays help, yet without QoS from switch to cloud, packets arrive out of order. Look, it’s simpler than you think: if timing drifts by even 150–250 ms, nuance collapses.

User side, the pain hides in the handoff. Interpreters juggle multiple return feeds, talk‑back, and floor audio while leaders toggle screens. Old rooms assumed one podium, one voice. Hybrid rooms juggle side chats, polls, and slide audio. When SIP trunks share fabric with video bursts, interpreters hear stutters. When edge computing nodes sit two networks away from the soft client, you get small but fatal gaps. People then overtalk to “catch up”—and meetings feel tense. The fix is not only more bandwidth; it is disciplined routing, channel isolation, and clear UX so an interpreter can trust the line every second.
Comparing What Comes Next
What’s Next
New technology principles flip the stack. Instead of patching translator audio into a general meeting bus, modern designs assign dedicated micro‑services for ingest, mix, and return, each with its own clock. Think of three anchors: deterministic buffering, per‑channel QoS, and observability. Deterministic buffering holds streams just enough to align words with slides; per‑channel QoS protects interpreter audio even when cameras spike; observability gives live metrics on jitter, packet loss, and endpoint power converters (yes, even power can skew audio). In a true hybrid conference, the room, the cloud, and the remote booth act as one pipeline—not a cluster of clever patches.
Comparatively, cloud‑first RSI with optional on‑prem media relays beats monolithic racks on resilience and clarity—provided the design guards the interpreter path. Set beamforming mics to conservative lobes; keep AEC local; send clean stems to the cloud mixer; return language channels on separate sockets. Edge relays trim round‑trip to under 120 ms; cloud mixers scale without adding hiss; and administrators get heat‑map alerts when a switch drops QoS—funny how the quiet alerts stop the loud problems. To choose well, apply three practical metrics: 1) latency, measured end‑to‑end for interpreted channels under live load, 2) channel integrity, verified by packet‑level continuity and failover to a secondary path, and 3) interpreter experience, rated on setup time, talk‑back clarity, and fatigue over a two‑hour session. Use these, and the room will speak with one voice, even across oceans. For a deeper technical baseline and product lineage, see TAIDEN.